

Avalanche
Avalanche Blockchain Consensus Algorithm

Before we get started, let us refresh our memory with what ‘Consensus Algorithm’ means. Consensus Algorithm (sometimes called Consensus Mechanism) is a mechanism to ensure that multiple nodes in a distributed system make the same decision, and for a blockchain, the most important decision is to decide which block should become the new block on the chain.
Before the advent of Avalanche’s consensus, there were two focal sets of consensus algorithms: Classical Consensus and Nakamoto Consensus.
Classical Consensus was achieved through multiple rounds of voting. Each node in the network communicates with other nodes to broadcast its decision. Since nodes need to communicate with other nodes in the entire network, members of network nodes need an accurate list of protocol members.
The Classical consensus algorithm works well with a small number of nodes, but its time complexity is outrageously high, resulting in high operating costs for the node network. At the same time, this algorithm cannot be extended to large decentralized networks that support user mobility.
The second set of consensus algorithm is the Nakamoto Consensus. That is what Bitcoin and many other Crypto Blockchain use. It uses the “Longest Chain Principle“, the chain that consumes the most work has an authoritative historical record.
Miners do not participate in voting verification, but hash and distribute their work. The bright side of the Nakamoto consensus algorithm is that it can scale to a large number of users without sacrificing performance.
The issue still remains that performance is not great. Any number of miner nodes can participate in or exit the block blasting process at will, which leads to slow block generation and block reorganization at any time, leading to changes in the storage contents on the chain.
The more times a new block and its chain are identified by network nodes, the less likely it is that a longer chain fork will replace it. But that doesn’t guarantee that longer chain forks won’t occur.
The understanding of those two Consensus brings us to the Avalanche Consensus Algorithm.
Avalanche Consensus Algorithm
It is a brand new consensus algorithm, and it is realized by Random subsampling. The mechanism protocol was invented and standardized by researchers at Cornell University, including Avalanche co-founders Emin Gun Sirer, Ted Yin, and Kevin Sekniqi. Below is a relatable illustration of the Avalanche Consensus Algorithm.

Assuming there are 1,000 meeting participants who need to decide together what to take for lunch: coffee or tea. Everyone has an initial preference, but they need to agree on the final plan. As a participant, you take a small random sample and ask 10 participants what they would like to have.
Seven people say coffee. It looks like most people want coffee, so now if someone asks you, you’ll say coffee. Subsequently, you perform another round of random sampling. You ask another group of 10 randomly selected people, and if most of them answer tea, you change your preference.
And if most people say coffee, you’ll say coffee again. So you get the same result from both samples. You can continue iterating through this process until you get the same result 100 times in a row. At this point, you think the final decision is made.
Since nodes only communicate with a fixed number of nodes in each round of sampling, the time complexity of message delivery in a single round of sampling is O(1) (often at a constant level). Unlike the Classical consensus algorithm, the complexity of message passing does not increase as the number of nodes increases. But how many rounds of random sampling are needed to get the final result? It depends on the size of the network.Thanks to our partners, you can find ties online to suit every preference and budget, from budget to top-of-the-range super stylish models.
The Avalanche Consensus is based on probability statistics. A node may repeatedly sample only a small number of nodes and draw incorrect conclusions. But the protocol is tunable.
We can make the probability of this happening extremely small, such as less than 0.0000000001%. Because of this high degree of predictability, Avalanche is final. Once intra-network transactions are decided, they are locked on the chain forever. There is no block reorganization at Avalanche.
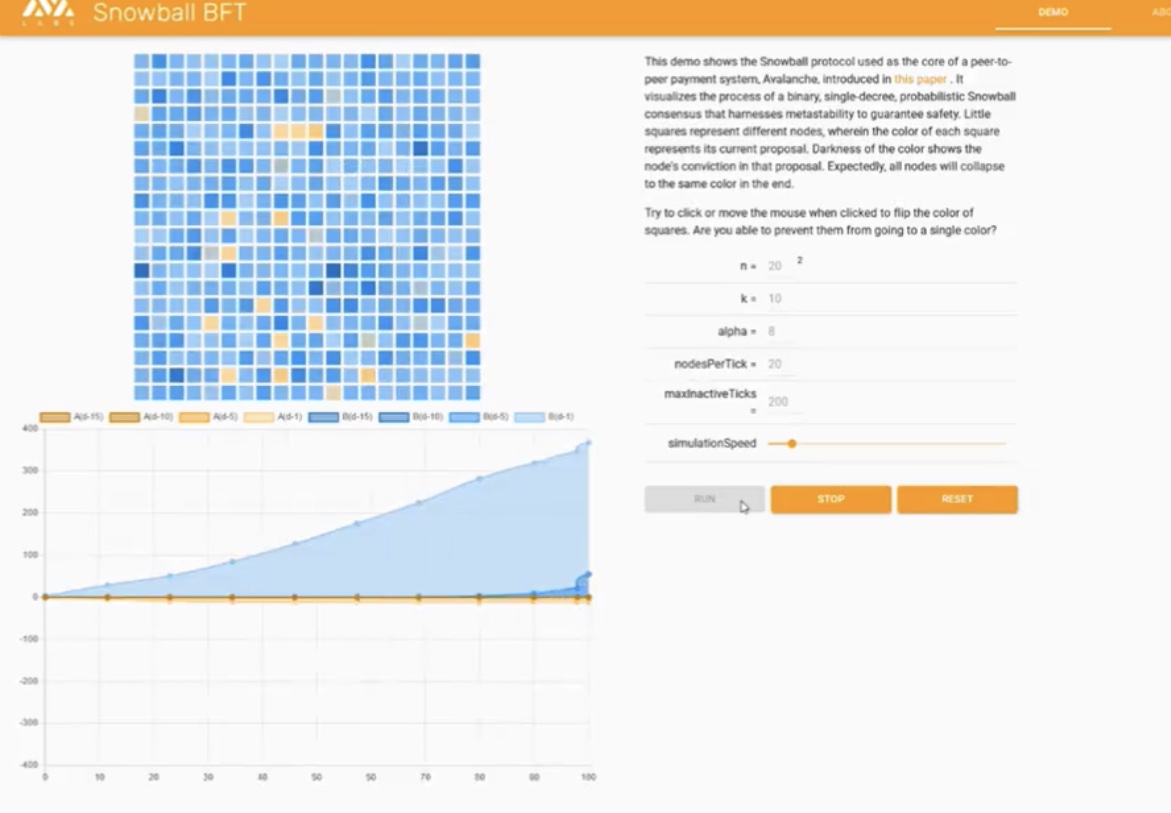
Source: Avalanche Whitepaper
Looking at the above visual representation of Avalanche Consensus Algorithm, one would see that after certain nodes are selected, the final result of multiple rounds of sampling is impossible to reverse.
Read Also:
VIN-FAST: Introducing the World’s Biggest Electric Vehicle NFT
Does all these sound too technical and obtuse? Breath in, breath out, go over it again with a clear mind, trust me it is going to get better. Now that we have an understanding of how it works, shall we look at the strengths of the Avalanche Consensus Algorithm.
- The Avalanche protocol has a high operating efficiency, but the limiting factors are message delay and network bandwidth. This means one can plug into the Avalanche network on low-spec hardware, without the need for specialized mining equipment, just servers in the middle tier. Some users even run Avalanche verification nodes on Raspberry Pi microcomputers.
- The protocol is static, running only when there is work to be done, without the ‘waste’ of a Proof-of-Work(POW) mechanism.
- The Avalanche Consensus Algorithm is environmentally friendly. Because the hardware requirements are very low, the impact on the environment is minimal.
- Avalanche can use any form of Sybil Protection Mechanism. We all know that Avalanche is a Proof-of-Stake(PoS) blockchain. But POS is not a consensus algorithm, it’s just a protection mechanism against Sybil attacks.
- Lastly, It is extremely fast to execute, Avalanche can process 4500 transactions per second and finalize in 1-2 seconds in simulation and practice.
Avalanche Consensus is configurable (the system can be configured to meet operational needs). It is essentially a new consensus protocol with no fixed code implementation.
Avalanche balances security with activity. If one-third of the network nodes are offline, the network process will slow down or stop until it recovers to a threshold level.
What do you think of this article? Let’s hear from you in the comment box!






















Pingback: Avalanche Blockchain Consensus Algorithm by Temitope Akintade – CryptoTvplus Events: NFT, DeFi, Bitcoin, Ethereum, Altcoin Events